Sledování šíření invazních druhů a včasný zásah proti nim je velké téma nejen vědy a ochrany přírody. Když totiž toto téma vezmeme doslova, jedná se i o sledování šíření různých nemocí a patogenů, a to nejen nemocí postihujících rostliny, ale i zvířata včetně nás lidí. Všichni jsme na vlastní kůži poznali, jakou paseku dokáže v naší společnosti napáchat nový malinkatý virus.
Abychom se však dobrali relevantním výsledkům, musíme se v našem poznání přírodních dějů neustále zlepšovat. Na jednu stranu musíme pořizovat kvalitnější záznamy o výskytu těchto druhů nebo nemocí, na stranu druhou bychom měli přicházet s novými nástroji pro jejich analýzu, modelování a tvorbu předpovědí. Začít se dá například tak, že budeme napřed sledovat výskyt nějakého běžně rozšířeného fenoménu a pomocí her a zkoušení se budeme snažit předpovídat, jak se bude daný fenomén rozšiřovat. Později pak můžeme naši předpověd ověřit a zjistit tak, jestli naše použité nástroje dávají smysl. A to je případ i tohoto článku.
Houbová nemoc hlohu
Spíše než o výzkum se v tomto případě jedná o jakousi dětskou zvídavost. Zajímalo mě totiž, proč mají některé keře hlohu na svých listech hnědé tečky. Nějak jsem tomu dlouhá léta nevěnoval pozornost, věděl jsem akorát, že se jedná o nějakou houbovou chorobu. Teprve později jsem se dozvěděl, že jde o houbu z rodu Diplocarpon, která přezimuje na spadaném listí. Přišlo mi to jako zajímavý příklad, který bych mohl prozkoumat. Jedná se víceméně o estetickou chorobu, která v malém množství hloh nezatěžuje (sám jsem hostitelem nějaké houby, tak vím, jak to dokáže být pro hloh nepříjemné, ale když si vlasy myju každý den, skoro žádné příznaky se neprojevují), navíc poměrně častou, bylo tedy teoreticky k dispozici velké množství dat, která na mě venku v přírodě čekala.
Jelikož se daná houba zdržuje na spadaném listí, myslel jsem si, že bude větší výskyt této choroby na daném místě souviset s blízkostí lesa nebo obecně většího množství listnatých stromů. Vyrazil jsem tedy ven a v různých prostředích napadené hlohy hledal. Nenašel jsem jich nějak hodně, ale pro můj zkušební příklad postačí. U každého nalezeného hlohu jsem si poznamenal, jaká byla vzdálenost od nebližšího lesa, vodního zdroje a od vesnice. Dále jsem si pak samozřejmě poznamenal specifika místa, kde se daný keř nacházel, a času v roce, kdy jsem keř navštívil a příznaky jsem pozoroval. Nakonec jsem jednoduše spočítal počet napadených listů. Jednoduché!
Tento postup lze mimochodem snadno zjednodušit pomocí aplikace Křivobjevy a umělé inteligence Křivoklaij, která spočítá vzdálenost daného místa od lesa a vesnice, neboli od tmavě zelené a šedé barvy na mapě. Tyto vzdálenosti jsou názorně ukázány na následujícím obrázku:

Pokud navíc v aplikaci Křivobjevy společnými silami v průběhu let nasbíráme dostatečné množství objevů, u kterých zadáme jejich prostředí, můžeme být ještě přesnější a určit vzdálenost například od nejbližšího dubového lesa. Každá značka na mapě má pod sebou barevné kolečko, které daný druh prostředí specifikuje. Dubový les je tak představován světle zelenou barvou. Podívejte se na následující obrázek:
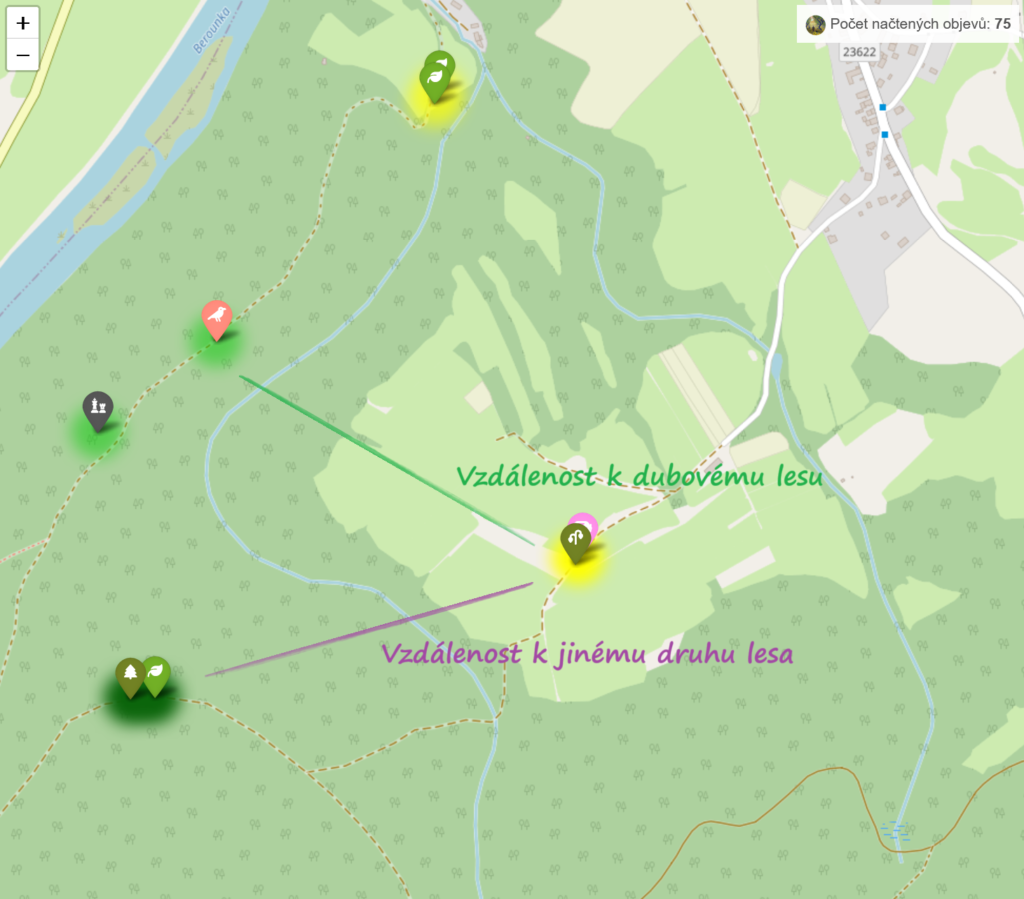
Nicméně pro tento příklad jsem si musel vystačit s mou odhadnutou vzdáleností, která nebyla z těchto objevů přesně spočítána. Celkové množství údajů, které jsem o každém jednotlivém hlohovém keři shromáždil, pak ukazuje následující tabulka. Tyto všechny údaje jsem chtěl zahrnout do analýzy a zjištění matematického vzorečku, který by mi pomohl odhadnout, kolik listů hlohu bude napadeno v závislosti na těchto údajích. Mohl bych pak později podle vzdálenosti a všech dalších údajů odhadnout, kolik bude mít daný keř zhruba napadených listů.
| Název údaje (proměnné) | Popis |
|---|---|
| T | Průměrná teplota za poslední dva týdny |
| V | Hustota vegetace v okolí |
| R | Dešťové srážky za poslední dva týdny |
| E | Nadmořská výška |
| dT | Vzdálenost od nejbližšího města nebo vesnice |
| dFi | Vzdálenost od nejbližšího pole |
| dW | Vzdálenost od nejbližšího vodního zdroje |
| dFo | Vzdálenost od nejbližšího lesa |
| S | Plocha nejbližšího pole |
| C | Odhadovaný výskyt dané choroby v daném měsící v roce |
| M | Měsíc v roce |
A samozřejmě jsem si u každého keře zaznamenal zmíněný počet napadených listů, což je zároveň proměnná, kterou bych si přál pomocí analýzy odhadovat, respektive ji předpovídat.
Tyto údaje jsem pak rozdělil na dvě poloviny. První polovina představovala takzvaná trénovací data, na kterých jsem chtěl vzoreček pro výpočet počtu napadených listů odvodit, a druhá polovina testovací data, pomocí kterých pak výsledný vzoreček otestuji, jestli dává smysl. Nedržel jsem se nějaké přesné metodiky, ani jsem data nezaznamenával s vědeckou pečlivostí. Naopak jsem to celé bral jako hru a testování nástroje, který jsem chtěl pro odvození tohoto vzorečku použít. Vzorečku, který pak lze použít na libovolné místo v našem kraji a který nám po zadání potřebných údajů (odvozených automaticky vzdáleností na mapě a času v roce) dokáže předpovědět, jak bude dané místo chorobou napadené, respektive kolik budou mít dané hlohové keře na daném místě v průměru napadených listů.
A jaký nástroj jsem chtěl vyzkoušet? Jedná se o takzvané genetické programování, které se na jednotlivé kandidáty na vzorečky dívá jako na jedince, kteří pak prochází simulovaným procesem evoluce. Jde vlastně o simulaci základních evolučních dějů pomocí počítače, tedy nikoliv o statistiku nebo matematické výpočty jako takové. Statistika a modelování se totiž běžně pro podobné případy používají a podle mého názoru jsou ne vždy přesné. Genetické programování tak může sloužit jako alternativa, případně doplněk, těchto běžně používaných statistických metod. Výstupy z obou typů nástrojů pak lze vzájemně porovnávat a zjistit některé zajímavosti. Neboť, jak jsem sám zjistil, genetické programování dokáže velice rychle a efektivně odfiltrovat ty údaje, které nejsou až tolik podstatné a které běžné statistické výpočty poměrně komplikují.
Napřed se ale společně podívejme na nastavení tohoto evolučního algoritmu. Jistě víte, že evoluce v přírodě probíhá nad populací z různě geneticky složených jedinců, kteří se takzvaným přírodním výběrem selektují a jejichž geny pomocí rozmnožování vstupují do dalších generací. Ty geny, které se v populaci udržují nejdéle, jsou považovány za úspěšné. Z nich jsou pak složení jedinci, v našem případě vzorečky, kdy ten nejúspěšnější vzoreček má nejvíce úspěšných, respektive nejdéle přežívajících, genů vhodných do daného prostředí. V našem případě je prostředím úloha odvození vzorečku pro výpočet napadených listů hlohu, prostředí, které se na rozdíl od přírody během výpočtu nemění.
Co se týče nastavení parametrů evolučního algoritmu v rámci Křivoklaije, pro začátek jsem nastavil velikost populace na 500 jedinců, počet generací, po kterých se algoritmus zastaví, na 100. Z každé populace se rovněž vybere 100 jedinců, kteří spolu budou soutěžit o možnost se rozmnožit. Pravděpodobnost mutace u nově vznikajícího jedince jsem nastavil na 10 % a pravděpodobnost, že daný jedinec vznikne rekombinací genů, na 90 %. Co se týče každého jedince, tedy vzorečku, maximální hloubka jeho stromové reprezentace byla omezena na 17 s tím, že se bere ohled i na to, aby byl vzoreček nejen co nejpřesnější vzhledem k naměřeným hodnotám, ale také co možná nejkratší.
Těmito nastaveními se nemusíte příliš zaobírat, jedná se jen o nastavení podmínek evoluce pro danou úlohu. Tento algoritmus jsem spustil několikrát za sebou a jednotlivé výsledky mezi sebou porovnával. Jelikož byl algoritmus spuštěný nad trénovacími daty, prováděl jsem následující ověřování i nad daty testovacími, abych zjistil, jestli se generace vyvíjí správným směrem ke globálnímu optimu (matematický pojem). Výsledný vzoreček, který jsem po asi třetím běhu algoritmu získal, má následující stromovou reprezentaci:
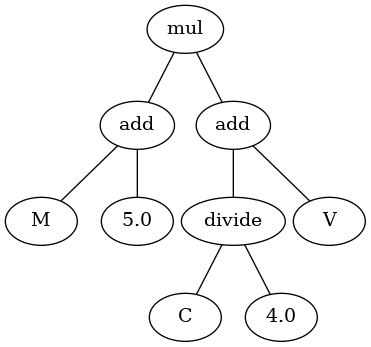
Tuto takzvanou stromovou reprezentaci lze snadno přepsat do matematického vzorečku. Písmena, tedy M, V a C, odpovídají názvům proměnných z tabulky výše:
$y = {\left(M + 5\right)\left({C \over{4}} + V\right)}$,
kde y je počet napadených listů na jednom keři.
Výsledný vzoreček je až podezřele jednoduchý, navíc neobsahuje mnohé z původně zkoumaných údajů. Například vzdálenost od nejbližšího lesa dFo úplně chybí, a přitom podle příspěvků na internetu a podle zjištěných dat samotných by přinejmenším nějakou roli hrát měla!
Naopak trochu překvapivou je závislost na aktuálním měsíci v roce M, který vstupuje do vztahu jak s odhadnutým výskytem nemoci v daném měsíci C, což překvapivé není, tak i s hustotou vegetace v okolí V. Je tedy vidět, že genetický algoritmus výrazně upřednostnil hustotu vegetace před vzdáleností k lesu, i když statisticky se vzdálenost od lesa jevila jako významná. Za vyzkoušení by stálo hustotu vegetace úplně z algoritmu vypustit.
Každopádně aproximace neboli odhad, který daný vzorec představuje, výrazně upřednostňuje časové hledisko oproti místu. Je to možné i z toho důvodu, že už je choroba v rámci Křivoklátska poměrně rovnoměrně rozšířená a vzdálenosti již nehrají (významnou) roli. Choroba prostě v daném měsíci dorazí a pak zase zmizí. V méně lesnatých krajích nebo za jiných podmínek by situace vypadala jinak. Stejně tak očividně moc nezávisí na průměrné teplotě, i když pro ověření by samozřejmě bylo potřeba sbírat data za více let s různými průměrnými teplotami a srážkami.
Nutno říct, že se nejedná o jediný vzoreček, který může evoluční algoritmus vrátit. Jedná se však o zajímavou aproximaci, která nám může pomoci otevřít nové obzory a zaměřit se na sbírání těch údajů, které se jeví jako významné pro sledování šíření daného invazního druhu nebo nemoci. 🙂